Customer acquisition managers of Banking, Financial Services and Insurance (BFSI), telecom, energy and utility, and other subscription businesses often struggle with acquiring new potential target customers to strengthen the business pipeline. What frustrates them is the low rate of conversion of these seemingly market-ready customers due to high risks associated with their profiles. This merits the consideration of using predictive logic to intelligently sift data from the past.
Let’s look at a scenario. You mine the rejected profiles of the past and find a significant number who have shown improvements in their financial behavior since the last risk assessment. Call them ‘rejected customers with potential’ or ‘ready for acceptance’, this could be potential gold in customer mining.
Most organizations use the application scorecard methodology as a decision support technique for customer acquisition, and the behavioral scorecard for tracking existing customers. The development, validation and continuous monitoring of such scorecards rely on the logistic regression model — they are based on previous performance as an indication of future behavior.
Application scorecards are more complex to validate than behavioral scorecards. This is due to the lack of information about the customer and the continuous population characteristic changes on which the good and bad population is segregated. And yet, the highly competitive market, the population attitude and continuous behavior shifts have made it imperative for such types of scorecards to be regularly reviewed and validated.
When lending decisions are based solely on the behaviors of accepted customers and with no benchmark parameters for the ‘rejected customers with potential’ group, it causes an unfavorable bias to reduce the potential pool for customer mining. Gaining new and better insights into the ‘rejected’ population as opposed to simply excluding these records from all modeling may be a more sustainable option. Here is where the Reject Inference (RI) technique becomes relevant.
RI Technique: Enhancing the Quality of Customer Mining
The RI technique is the process of assigning a theoretical performance to applicants who had previously been declined. This is the equivalent of saying that if all the rejects had been accepted, some of them would have exhibited good payment behavior, while others would have displayed bad payment behavior. Here, we can use RI to identify the rejects who would have been good payers and accordingly adjust the application scorecard. This allows the mining of a potential customer database that is vast.
RI in Three Easy Stages
The simplest way to include information on rejects is to evaluate them using the existing scorecard criteria of ‘good’ and ‘bad’ (rejected loan applications can be used afterwards to adjust the scorecard).
The performance of an applicant is tracked for a specific period and classified as good or bad. As a first step, the data is classified into the following four blocks.
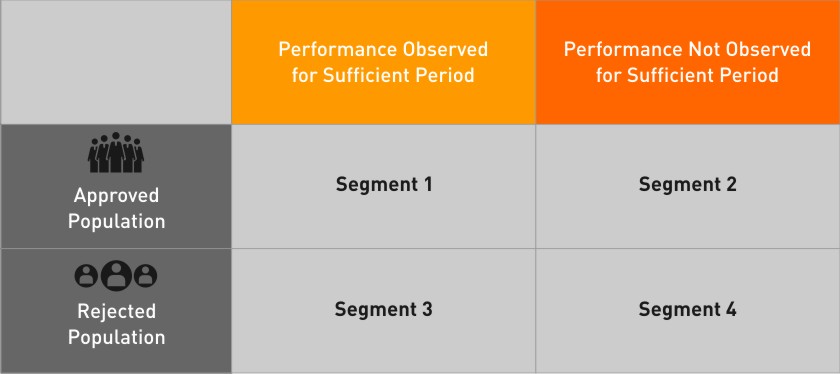
Stage 1
- Segment 1 is divided into good and bad, depending on their actual performance.
- For Segment 2, any applicant that satisfies the criteria for being bad is defined to be bad. (The remaining accounts are excluded from the analysis due to lack of sufficient performance window.)
- RI is done on Segment 3, based on the good-bad information obtained from the Segment 1 and Segment 2 population (Accordingly, this population is divided into ‘Inferred Good‘ and ‘Inferred Bad’.)
- Segment 4 is entirely left out of the analysis.
Stage 2
- A good-bad model is developed on the Segment 1 population together with the bad obtained from Segment 2. For the purpose of this model, ‘Good’ is defined from Segment 1 and ‘Bad’ from both Segments 1 and 2.
- On the basis of a good-bad model developed from the above population, the Segment 3 is now scored on the criteria of this ‘good-bad’ model to derive P (bad).
- A combination of P (bad) and Heller Scores (with a reasonable cut-off for both) is then used to identify the ‘Inferred Good’ and ‘Inferred Bad’ accounts in Segment 3.
- The ‘Good’ and ‘Bad’ (from Segments 1 and 2) and the ’Inferred Good’ and ‘Inferred Bad’ (from Segment 3) are clubbed together to form the final set of good and bad.
Stage 3
Scorecard validation is an integral part of the scorecard construct as it checks whether the newly developed scorecard is valid and robust. This stage sets out to provide the required evaluation of the scorecard’s effectiveness in predicting risks on the population that it is built on.
Validation is done on both ‘hold-out’ and ‘out-of-time’ samples. Measures such as Gini Co-efficient, K-S Statistic and Divergence are used to measure the true strength of the scorecard and to remove false positives.
RI is an effective technique to increase growth and revenue by increasing the application acceptance while recognizing the associated risks of bad customers. It may be a good idea to look for the ‘good’ in the ‘bad’. After all, ‘bad’ may not be all that bad.